保活
保活方法有以下几种:
1.长连接和心跳保活
2.JobSheduler进程重生
3.一像素进程保活
4.双进程保活
5.腾讯终极永生术(Native拉活)
其中史上最强Android保活思路:深入剖析腾讯TIM的进程永生技术这篇文章有较完全的保活技术文章总结
一.心跳保活
心跳保活的实现要完成三点:1.建立长连接2.固定时间发送心跳包3.服务端超时后要重连
长连接介绍
通信双方进行TCP链接后进行通信,结束后不主动关闭链接 优点:通信速度快,免去了DNS解析时间,以及三次握手四次分手的时间,避免短时间内重复连接所造成的信道资源 & 网络资源的浪费
心跳的实现

- 连接后主动到服务器Sync拉取一次数据,确保连接过程的新消息。
- 心跳周期的Alarm唤醒后,一般有几秒的cpu时间,无需wakelock。
- 心跳后的Alarm是为了防止发送超时,如服务器正常会包,该Alarm取消。
- 如果心跳后发送超时了,那么要和服务器重新建立连接拉取数据
- 如果服务器回包,系统通过网络唤醒,无需wakelock。
流程基于两个系统特性:
- Alarm唤醒后,足够cpu时间发包。
- 网络回包可唤醒机器
动态心跳
动态心跳引入下列状态:
- 前台活跃态:亮屏,微信在前台,周期为minHeart(4.5min),保证体验
- 后台活跃态:微信在后台10分钟内,周期为minHeart(4.5min),保证体验
- 自适应计算态:步增心跳,尝试获取最大心跳周期(sucHeart)
- 后台稳定态:通过最大周期,保持稳定心跳
自适应计算态流程:
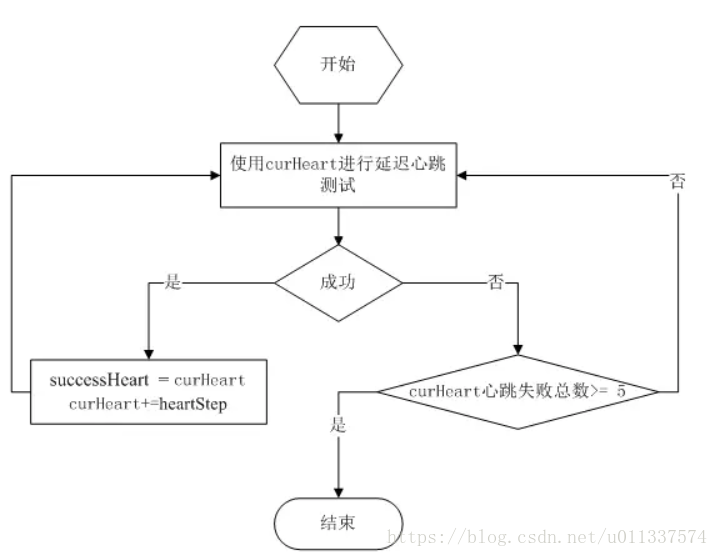
在自适应态:
- curHeart初始值为minHeart,步增(heartStep)为1分钟
- curHeart失败5次,意味着整个自适应态最多只有5分钟无法接受消息
- 结束后,如果sucHeart > minHeart,会减去10s(避开临界),为该网络下的稳定周期
稳定态的退出:
sucHeart会对应网络存储下来,重启后正常使用。考虑到网络的不稳定,如NAT超时变小,用户地理位置变换。当发现sucHeart连续失败5次,sucHeart置为minHeart,重新进入自适应状态。
参考链接:
正确理解IM长连接的心跳及重连机制,并动手实现(有完整IM源码)
二.JobSheduler进程重生
JobScheduler 简单来说就是一个系统定时任务,在app达到一定条件时可以指定执行任务,且如果app被强迫终止,此前预定的任务还可执行。
JobScheduler是用于计划基于应用进程的多种类型任务的api接口。当任务执行时,系统会为应用持有WakeLock,所以应用不需要做多余的确保设备唤醒的工作。
JobService继承自Service,是用于处理JobScheduler中规划的异步请求的特殊Service
JobSheduler进程重生关注重点就是系统服务获取:
var mJobScheduler = ctxt.getSystemService(Context.JOB_SCHEDULER_SERVICE) as JobScheduler
参考链接:
Android 进程保活(五)JobSheduler进程重生
三.一像素进程保活
1像素保活方案就是我们在手机锁屏时开启一个Activity,为了不让用户有感知,让这个Activity大小为1像素并设置透明无切换动画。在开启屏幕时把这个Activity关掉。
原理:主要是通过提高oom_adj的优先级可以使我们的app被系统杀死的概率变低。
实现一像素保活要完成:1.设置一像素Activity 2.注册监听锁屏开启、关闭广播接收器来完成控制一像素Activity开启和关闭
创建一像素Activity
1 | package com.baweigame.mvvmdemoapplication; |
参考链接:
四.双进程保活
双进程守护的思想就是,两个进程共同运行,如果有其中一个进程被杀,那么另一个进程就会将被杀的进程重新拉起,相互保护,在一定的意义上,维持进程的不断运行。
双进程守护的两个进程,一个进程用于我们所需的后台操作,且叫它本地进程,另一个进程只负责监听着本地进程的状态,在本地进程被杀的时候拉起,于此同时本地进程也在监听着这个进程,准备在它被杀时拉起,我们将这个进程称为远端进程。
由于在 Android 中,两个进程之间无法直接交互,所以我们这里还要用到 AIDL (Android interface definition Language ),进行两个进程间的交互。
参考链接:
五.Native拉活
原理:简单来说,两个线程建立文件锁,并fork出两个子线程,子线程也相互建立文件锁,当一个线程被杀死,另一个线程的子线程立马拉活被杀死的线程
保活的底层技术原理
一般来说,系统杀进程有两种方法,这两个方法都通过 ActivityManagerService 提供:
- killBackgroundProcesses
- forceStopPackage
在原生系统上,很多时候杀进程是通过第一种方式,除非用户主动在 App 的设置界面点击「强制停止」。不过国内各厂商以及一加三星等 ROM 现在一般使用第二种方法。第一种方法太过温柔,根本治不住想要搞事情的应用。第二种方法就比较强力了,一般来说被 force-stop 之后,App 就只能乖乖等死了。
因此,要实现保活,我们就得知道 force-stop 到底是如何运作的。既然如此,我们就跟踪一下系统的 forceStopPackage 这个方法的执行流程:
1 | public void forceStopPackage(final String packageName, int userId) { |
在这里我们可以知道,系统是通过 uid 为单位 force-stop 进程的,因此不论你是 native 进程还是 Java 进程,force-stop 都会将你统统杀死。我们继续跟踪forceStopPackageLocked 这个方法:
1 | final boolean forceStopPackageLocked(String packageName, int appId, |
这个方法实现很清晰:先杀死这个 App 内部的所有进程,然后清理残留在 system_server 内的四大组件信息;我们关心进程是如何被杀死的,因此继续跟踪killPackageProcessesLocked,这个方法最终会调用到 ProcessList 内部的 removeProcessLocked 方法,removeProcessLocked 会调用 ProcessRecord 的 kill 方法,我们看看这个kill:
1 | void kill(String reason, boolean noisy) { |
这里我们可以看到,首先杀掉了目标进程,然后会以uid为单位杀掉目标进程组。如果只杀掉目标进程,那么我们可以通过双进程守护的方式实现保活;关键就在于这个killProcessGroup,继续跟踪之后发现这是一个 native 方法,它的最终实现在 libprocessgroup中,代码如下:
1 | int killProcessGroup(uid_t uid, int initialPid, int signal) { |
注意这里有个奇怪的数字:40。我们继续跟踪:
1 | static int KillProcessGroup(uid_t uid, int initialPid, int signal, int retries) { |
循环 40 遍不停滴杀进程,每次杀完之后等 5ms,循环完毕之后就算过去了。
看到这段代码,我想任何人都会蹦出一个疑问:假设经历连续 40 次的杀进程之后,如果 App 还有进程存在,那不就侥幸逃脱了吗?
实现方法
那么,如何实现这个目的呢?我们看这个关键的 5ms。假设,App 进程在被杀掉之后,能够以足够快的速度(5ms 内)启动一堆新的进程,那么系统在一次循环杀掉老的所有进程之后,sleep 5ms 之后又会遇到一堆新的进程;如此循环 40 次,只要我们每次都能够拉起新的进程,那我们的 App 就能逃过系统的追杀,实现永生。是的,炼狱般的 200ms,只要我们熬过 200ms 就能渡劫成功,得道飞升。不知道大家有没有玩过打地鼠这个游戏,整个过程非常类似,按下去一个又冒出一个,只要每次都能足够快地冒出来,我们就赢了。
现在问题的关键就在于:如何在 5ms 内启动一堆新的进程?
再回过头来看原来的保活方式,它们拉起进程最开始通过am命令,这个命令实际上是一个 java 程序,它会经历启动一个进程然后启动一个 ART 虚拟机,接着获取 ams 的 binder 代理,然后与 ams 进行 binder 同步通信。这个过程实在是太慢了,在这与死神赛跑的 5ms 里,它的速度的确是不敢恭维。
后来,MarsDaemon 提出了一种新的方式,它用 binder 引用直接给 ams 发送 Parcel,这个过程相比 am命令快了很多,从而大大提高了成功率。其实这里还有改进的空间,毕竟这里还是在 Java 层调用,Java 语言在这种实时性要求极高的场合有一个非常令人诟病的特性:垃圾回收(GC);虽然我们在这 5ms 内直接碰上 gc 引发停顿的可能性非常小,但是由于 GC 的存在,ART 中的 Java 代码存在非常多的 checkpoint;想象一下你现在是一个信使有重要军情要报告,但是在路上却碰到很多关隘,而且很可能被勒令暂时停止一下,这种情况是不可接受的。因此,最好的方法是通过 native code 给 ams 发送 binder 调用;当然,如果再底层一点,我们甚至可以通过 ioctl 直接给 binder 驱动发送数据进而完成调用,但是这种方法的兼容性比较差,没有用 native 方式省心。
通过在 native 层给 ams 发送 binder 消息拉起进程,我们算是解决了「快速拉起进程」这个问题。但是这个还是不够。还是回到打地鼠这个游戏,假设你摁下一个地鼠,会冒起一个新的地鼠,那么你每次都能摁下去最后获取胜利的概率还是比较高的;但如果你每次摁下一个地鼠,其他所有地鼠都能冒出来呢?这个难度系数可是要高多了。如果我们的进程能够在任意一个进程死亡之后,都能让把其他所有进程全部拉起,这样系统就很难杀死我们了。
新的黑科技保活中通过 2 个机制来保证进程之间的互相拉起:
- 2 个进程通过互相监听文件锁的方式,来感知彼此的死亡。
- 通过 fork 产生子进程,fork 的进程同属一个进程组,一个被杀之后会触发另外一个进程被杀,从而被文件锁感知。
具体来说,创建 2 个进程 p1, p2,这两个进程通过文件锁互相关联,一个被杀之后拉起另外一个;同时 p1 经过 2 次 fork 产生孤儿进程 c1,p2 经过 2 次 fork 产生孤儿进程 c2,c1 和 c2 之间建立文件锁关联。这样假设 p1 被杀,那么 p2 会立马感知到,然后 p1 和 c1 同属一个进程组,p1 被杀会触发 c1 被杀,c1 死后 c2 立马感受到从而拉起 p1,因此这四个进程三三之间形成了铁三角,从而保证了存活率。
参考链接:
史上最强Android保活思路:深入剖析腾讯TIM的进程永生技术